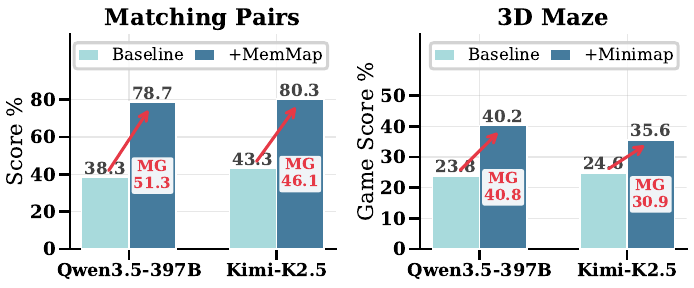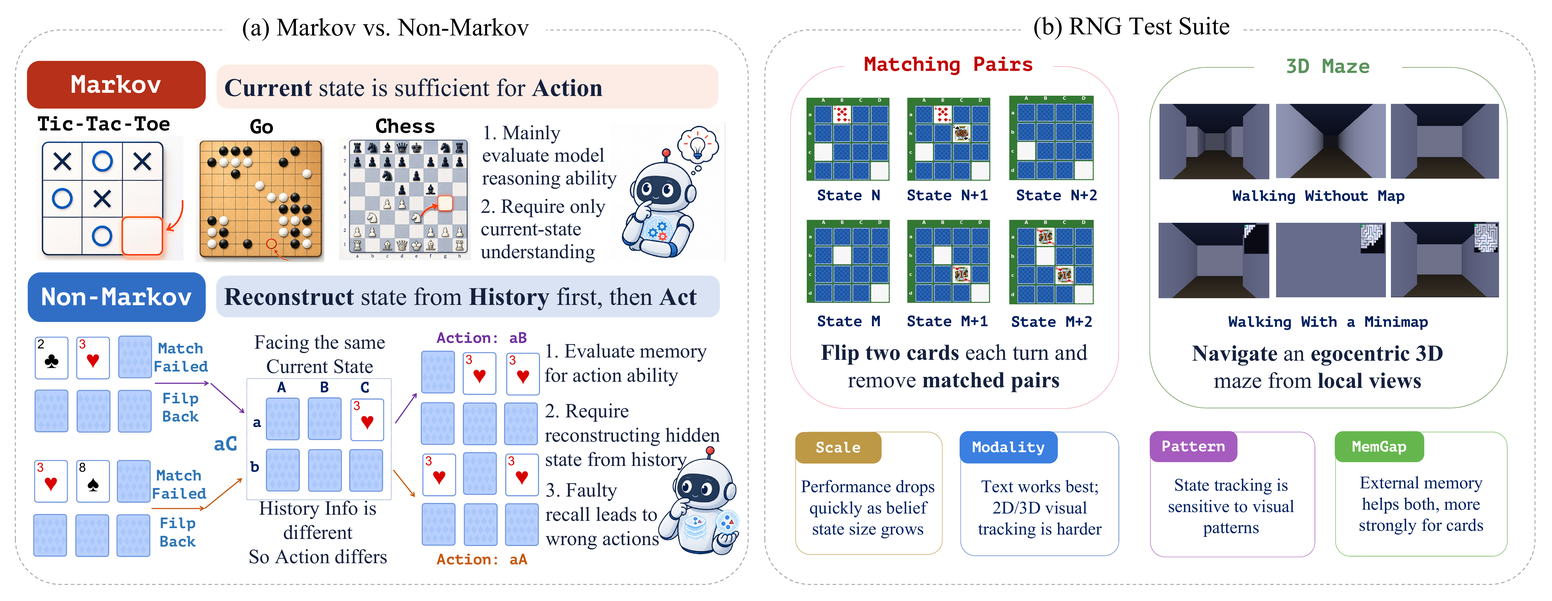




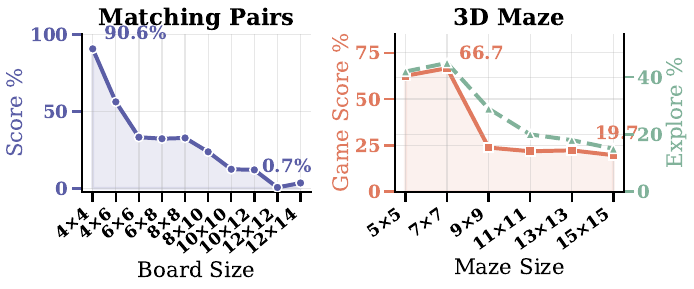
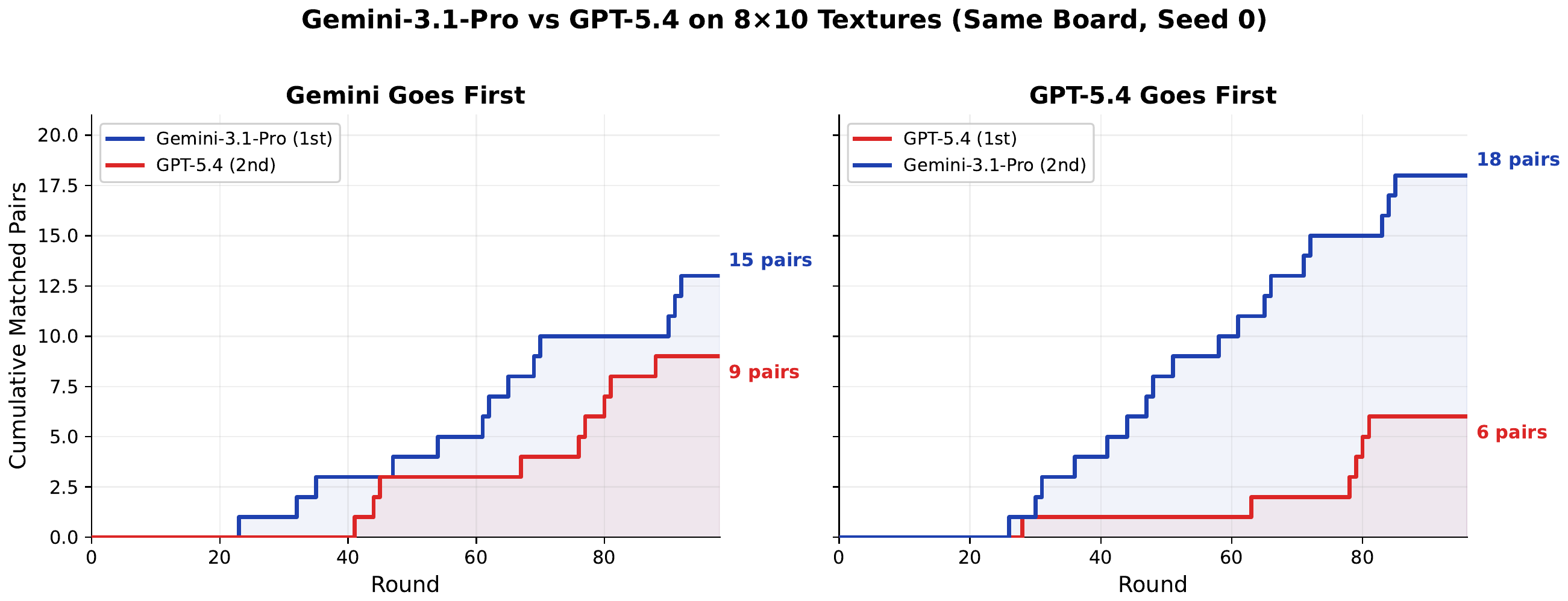
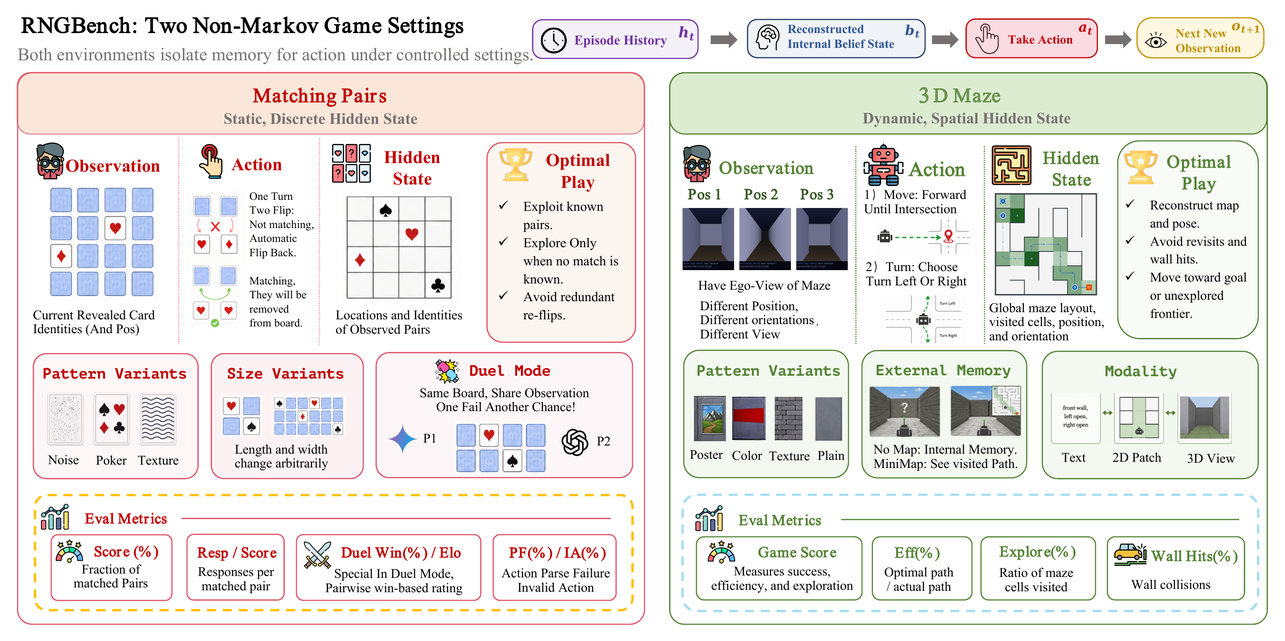




For each model we run two conditions on the same instance:
- Normal — the model sees only the current observation plus the in-context history.
- Oracle — the true hidden state is injected into the prompt at every step.
MemoryGap(m) = (1 − S(m) / S*(m)) × 100 %
A large gap localizes the bottleneck to belief-state reconstruction. A small gap points to perception, decision-making, or rule understanding.